Datenbanksysteme Klausurvorbereitung
Entwurfstheorie
Funktionale Abhängigkeiten
- Funktionale Abhängigkeiten (functional dependencies oder FD) sind statische Integritätsbedingungen. Diese sind semantische Bedingungen, um die Menge der Datenbankzustände einzuschränken.
- FDs sind Teil der Informationsanforderungen und werden in Absprache mit dem Anwender bei der Anforderungsanalyse gewonnen
Definition - funktionale Abhängigkeit:
Seien Teilmengen eines Relationenschemas . ist von funktional abhängig oder bestimmt funktional, geschrieben , genau dann wenn zu jeder Relation und jedem Wert in genau ein Wert in gehört:
- Für alle
Beispiel
Lieferant()
Funktionale Abhängigkeiten:
{LName} → {LAdr}
- ein Lieferantenname bestimmt eindeutig seine Adresse
{LName, Ware} → {Preis}
- {LName, Ware} bestimmt eindeutig den Preis
{LName} → {LName} (trivial)
{LName, Ware} → {Ware} (trivial)
{LName, Ware} → {LAdr} (partiell)
Überprüfung von FDs
Funktionale Abhängigkeiten sind wichtige Regeln, um die Datenqualität sicherzustellen. Sollte in einer Relation die FD erfüllt sein, so darf folgende SQL-Anfrage kein Ergebnis liefern:
select A, count(distinct B)from rgroup by Ahaving (count(distinct B) > 1)Diese Überprüfung garantiert aber nicht, dass auch zukünftig die FD erfüllt ist.
Funktionale Abhängigkeiten sind wichtige Regeln, um die Datenqualität sicherzustellen.
- Beim Einfügen eines neuen Tupels (..., a, ..., b, ...) in die Relation muss vorher überprüft werden, ob die folgende Anfrage leer ist:
xxxxxxxxxxselect *from rwhere A = a and B <> bZiel von FDs
Hohe Datenqualität
- Erfassung aller funktionaler Abhängigkeiten in einer Anwendung → Menge von FDs
Geringe Kosten, um die Datenqualität zu prüfen
Anlegen eines Index für jede FD
Zwar kann jede FD in logarithmischer Zeit geprüft werden, aber die Anzahl der FDs kann sehr hoch sein
Minimierung der Anzahl der FDs
Gibt es eine zu äquivalente Menge , die
- mit weniger FDs als auskommt
- und jede FD aus F auch aus abgeleitet werden kann?
Vorgehensweise - Minimierung der Anzahl der FDs
Ziel: Zu einer gegebenen Menge an FDs soll eine möglichst kleine äquivalente Menge von FDs berechnet werden.
Naiver Ansatz
- Ableitung aller FDs für eine vorgegebene Menge → Hülle
- Teste, ob eine FD in liegt
Effizienterer Ansatz
Direkte Überprüfung, ob eine FD aus einer vorgegebenen Menge ableitbar ist.
Erstellung einer minimalen Repräsentantenmenge , so dass alle FDs in aus ableitbar sind
- Beim Einfügen eines neuen Tupels genügt es die Regeln in zu überprüfen
Vorgehensweise
- Berechne aus die Menge aller aus ableitbaren FDs
- Verkleinere F so, dass aus der reduzierten Menge immer noch abgeleitet werden kann
Definition - Besondere FDs
Eine FD ist trivial, wenn gilt
Eine FD heißt voll, wenn es keine echte Teilmenge gibt, so dass gilt.
- Gibt es eine solche Teilmenge , dann heißt partielle Abhängigkeit
Seien und (aber nicht ). Sei und gelte . Dann ist transitiv abhängig von
Hülle einer Menge von FDs
Zu einer gegebenen Menge von FDs soll die Menge aller gültigen FDs berechnet werden.
- wird als die Hülle von bezeichnet.
Zur Berechnung von werden folgende Regeln genutzt (Armstrong Axiome):
- Reflexivität: Sei . Dann gilt stehts
- Verstärkung: Falls gilt, dann gilt auch
- Transitivität: Falls und , dann gilt auch
Alle gültigen FDs in können mit Hilfe dieser Regeln auch hergeleitet werden.
Ableitungsregeln
Trotz der Eigenschaften der Armstrong-Axiome ist es komfortabler noch folgende Regeln zu benutzen:
- Vereinigungsregel: Falls und gilt, dann gilt auch
- Dekompositionsregel: Falls gilt, dann gilt auch und
- Pseudotransivität: Falls und gilt, dann auch gilt auch
Berechnung Hülle per Algorithmus
Algorithmus zur Berechnung der Hülle mit gegebenen F (Menge der FDs einer Anwendung) und A (alle Attribute die von A funktional bestimmt werden)
xxxxxxxxxxHülle(F,A):Erg = A // A → A trivialWhile(Erg ändert sich): Foreach(B → C in F): if(B ⊆ Erg): Erg = Erg + Creturn ErgBeispiel: Hüllenberechnung
Gesucht ist Hülle
- =
- =
- =
- = und der Algorithmus terminiert
- =
Erklärung zu den einzelnen Schritten:
- Trivialer Fall, Füge hinzu (noch vor der Schleife im Algorithmus)
- Wir gehen in die Schleife und schauen, ob die linken Seiten unserer FDs jeweils schon vollständig im Ergebnis () enthalten sind. Dies ist offensichtlich bei der Fall, also können wir unserem Ergebnis hinzufügen.
- Da die FD existiert und eine Teilmenge des Ergebnis ist, kann und dem Ergebnis hinzugefügt werden.
Kanonische Überdeckung
Ziel: Minimierung der FDs einer Anwendung (Menge )
- Finden einer äquivalenten Menge , die mit weniger FDs auskommt
- Dazu bilden der Hülle
- Anschließendes Verkleinern der Menge ohne Informationsverlust
- Finden der kanonischen Überdeckung , so dass minimale Repräsentantenmenge mit =
Algorithmus
Gegeben: Menge mit funktionalen Abhängigkeiten
Führe für jede FD aus F die Linksreduktion durch:
Überprüfe für alle , ob überflüssig ist, d.h. ob Hülle
Ist dies der Fall, ersetze in durch
Führe für jede verbliebende FD die Rechtsreduktion durch:
Überprüfe für alle , ob überflüssig ist, d.h. ob Hülle
Ist dies der Fall, wird durch ersetzt
Entferne die FDs der Form (die im 2-ten Schritt entstanden sind)
Ersetze alle FDs der Form durch ...
Beispiel: Berechnung kanonische Überdeckung
Schritt 1: Linksreduktion
Info: Einelementige linke Seiten werden übersprungen.
, A ist überflüssig, da in der Hülle von enthalten ist: Hülle. Ersetze also mit .
Wir erhalten also:
Schritt 2: Rechtsreduktion
Fragestellung bei der ersten FD : Kommen wir, wenn wir weglassen trotzdem irgendwie von nach ? Antwort: Nein! Wir kommen von nur nach , aber von nicht mehr weiter. muss also weiterhin enthalten bleiben.
Führt man diesen Schritt für alle FDs aus erhält man:
Schritt 3: Entferne FDs der Form
Schritt 4: Fasse alle FDs mit gleicher linker Seite zu einer zusammen
Verlustlosigkeit, Hüllentreue Zerlegung
Zerlegung von Relationen
- Zur Vermeidung von Anomalien zerlegen wir die Relation in Relationen
- Es darf kein Informationsverlust entstehen und die ursprüngliche Relation muss (durch z.B. natural join) reproduzierbar sein
Definition verlustlose Zerlegung:
Sei zerlegt in und , die Zerlegung ist verlustlos, falls:
Zusätzlich wollen wir, dass die FDs lokal auf den zerlegten Relationen prüfbar sind, daraus ergibt sich folgende Definition.
Definition hüllentreue Zerlegung:
Seien lokale Mengen von FDs für die Relationen . Eine Zerlegung heißt hüllentreu, falls gilt:
=
Beispiel: Zerlegung
Sei und eine Zerlegung von RS. Zeigen oder widerlegen Sie, ob die folgende Zerlegung von verlustlos und hüllentreu ist.
Verlustlosigkeit:
Aus der Definition folgt, dass entweder oder gelten muss.
Wir sehen, dass also gilt. Somit ist die Zerlegung verlustlos.
Hüllentreue:
Hierfür schauen wir, ob alle FDs aus in den beiden Schemata und "untergebracht" werden können. Beispielsweise könnte in untergebracht werden, da sowohl , als auch in dieser Relation enthalten sind. Somit ergibt sich:
Also und somit ist die Zerlegung auch hüllentreu.
Normalformen
Normalformen sollen einen guten Datenbankentwurf garantieren.
Schlüsselkandidaten: Gibt es mehrere Schlüssel in einer Relation, nennt man diese auch Schlüsselkandidaten Prime Attribute: Attribute, die Teil eines Schlüsselkandidaten sind Nicht-Prime Attribute: Attribute, die nicht Teil eines Schlüsselkandidaten sind
1. Normalform
Alle Attribute können nur atomare, nicht weiter zerlegbare Werte annehmen.
2. Normalform
Jedes Nicht-Prime Attribut ist von jedem Schlüsselkandidaten voll funktional abhängig.

In diesem Beispiel ist TeilMenge voll funktional vom Schlüsselkandidaten (ProjektId, TeilId) abhängig. Projektleiter ist jedoch nur von ProjektId abhängig, daher wäre es nur partiell und nicht voll funktional vom Schlüsselkandidaten abhängig. Also muss die Relation in zwei Relationen aufgeteilt werden, um die 2. NF zu erhalten.
Info: 2. NF kann nur verletzt sein, wenn der Schlüssel zusammengesetzt ist.
3. Normalform
Es gibt kein Nicht-Prime Attribut, welches von einem Schlüsselkandidaten transitiv abhängig ist.

Projektleiter ist direkt abhängig von ProjektId, ProjektLeiterEmail jedoch nur von Projektleiter und somit transitiv vom abhängig vom Schlüsselkandidaten. Um die Relation in die 3. NF zu bringen muss auch hier wieder eine neue Relation erzeugt werden.
Synthesealgorithmus für die 3. NF (wenn es komplexer wird)
Ziel: Zerlegung einer Universalrelation in Relationen unter folgenden Bedingungen:
- Kein Informationsverlust
- Bewahrung der funktionalen Abhängigkeiten
- Die erzeugten Relationen erfüllen die 3. NF
Eingabe:
- Menge der Attribute
- Menge der FDs
Ausgabe:
- Relationenschemata in 3. NF
Ablauf:
Berechnung der kanonischen Überdeckung von
Für jede :
- Erzeuge Relationenschema
- Ordne alle FDs zu
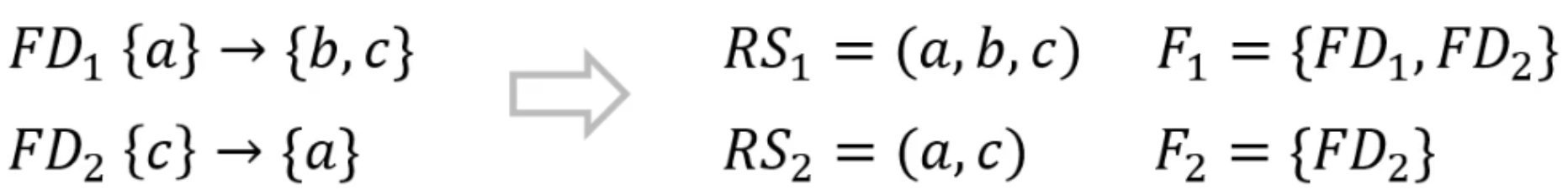
Falls kein erzeugtes Schema den Kandidatenschlüssel von enthält, erzeuge Relation mit Schema und .
- Nur wenn der Kandidatenschlüssel nicht schon vollständig in einer der Relationen enthalten ist. Diese Relation hat dann genau die Attribute des Schlüsselkandidaten und keine funktionalen Abhängigkeiten
Eliminiere alle Schemata, die in einem anderen Schema enthalten sind.
- Beispiel: ist im obigen Beispiel bereits vollständig in enthalten und kann somit eliminiert werden.
Synthesealgorithmus liefert ein Datenbankschema mit folgenden Eigenschaften:
- Alle Relationen sind in der 3. NF
- Hüllentreu
- Kein Informationsverlust
Beispiel: Synthesealgorithmus bei gegebener kanonischer Überdeckung
Schritt 2 (Relationenschemata erzeugen):
mit FDs mit FDs mit FDs
Schritt 3:
Da Schlüsselkandidat in diesem Beispiel unbekannt, muss man diesen erst herausfinden: Alle Attribute können über und erreicht werden, daher ist der Schlüssel . Da in keiner der Relationen aus Schritt 2 vollständig enthalten ist, muss entsprechend eine 4. Relation erzeugt werden:
Schritt 4:
Keine Relation kann eliminiert werden, da keine Relation vollständig in einer anderen Relation enthalten ist.