Datenbanksysteme Klausurvorbereitung
SQL
SQL besteht aus folgenden Teilsprachen
- DDL (Data Definition Language): Erzeugen von Datenstrukturen wie z. B. Datenbanken, Relationen, Indexe, Sichten
- DML (Data Manipulation Language): Einfügen, Löschen, Ändern von Daten, Anfragen
Sichten und Ebenen
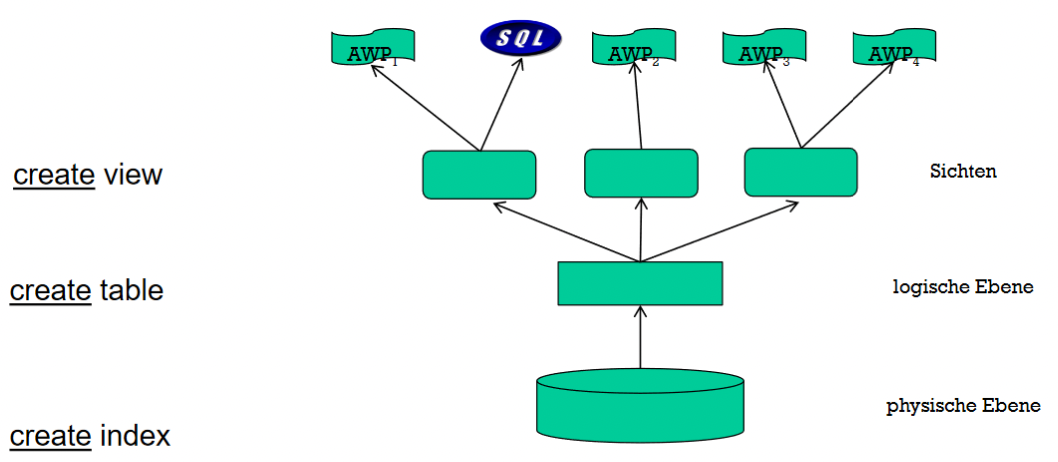
Datenbanken/Relationen:
Syntax Datenbank/Relation anlegen:
create database <name>create table <relname>(<Relationenkomponente> [, <Relationenkomponente>])create database <name>create table <relname>(<Relationenkomponente> [, <Relationenkomponente>])Syntax Relationenkomponente:
Deklaration eines Attributs oder einer Integritätsbedingung
Attributname Typ [Integritätsbedigung]Beispiel:
create table Maschinen(mnr int primary key, mname varchar(10));
Integritätsbedigung:
- Primary key
- Not null
- Default
- References Abteilung(abtnr): Fremdschlüsselbedingungauf das Attribut abtnrderRelation Abteilung
- Separate Integritätsbedingung (Primärschlüssel mit 2 Attributen): constraint
primary key (< Attributname>,< Attributname>)
Beispiel:
create table Personal(pnr int primary key, pname varchar(10) not null, vorname varchar(10), abtnr int references Abteilung(abtnr), lohn int default 20000); create table pmzuteilung(pnr int references Personal(pnr), mnr int references Maschinen(mnr), note int, constraint pk primary key (pnr,mnr));Löschen/Ändern:
| Operation | Syntax |
|---|---|
| Datenbank löschen | drop database |
| Relation löschen | drop table |
| Relation ändern | alter table |
Tupel
Einfügen:
Syntax:
insert into <Relationen-Name> [(<Attributname> [, <Attributname>]*)] values (<Konstante> [, <Konstante>]*)Beispiel:
insert into PMZuteilung values (51, 84, 2), (82, 101, 2);Löschen:
Syntax:
delete from <Relationen-Name> where <Bedingung>Beispiel:
delete from PMZuteilung where note < 4
Sicherstellung der Integritätsbedingungen
Nach dem Einfügen wird i. A. überprüft, ob die Integritätsbedingung noch erfüllt sind.
Wenn nicht, wird die Operation rückgängig gemacht und ein Fehler gemeldet.
Anfragen
Grundschema:
Syntax:
select <Liste von Attributnamen> from <Liste von Relationnamen> [where <Bedingung>]Selektion
- Atomare Ausdrücke mit Operatoren: =,>,<,!=,<=,>=, ...
- and, or und not in where
- Verwendung von Quantoren: exists, any, some, all
- Mengenoperatoren: in, not in
- Spezialoperatoren: like (für Zeichenketten)
Vereinigung
(Duplikate werden eliminiert)
Beispiel:
select pnrfrom PMZuteilungwhere Note < 4 unionselect pnrfrom Personalwhere abtnr = 10Differenz
Entsprechend gelten bei except die Regelnder Mengensemantik.
Voraussetzung: Schemaverträglichkeit
Beispiel:
select pnr from PMZuteilung exceptselect pnr from Personal where abtnr = 10;Umbenennung
Syntax:
select <Attributname> as <neuer Attributname> from <Liste von Relationnamen>Beispiel:
select mnr as nummer, mname as namefrom Maschinen;Kartesisches Produkt
Attribute der Schemata müssen in SQL nichtdisjunkt sein.
Ein Join kann durch eine zusätzliche where-Klausel formuliert werden.
Beispiel:
select *from Abteilung, Personal;
Multimengensemantik
Projektion
Ohne distinct keine Duplikatbeseitigung: select pnr from PMZuteilung;
Vereinigung (union all)
select pnr from PMZuteilungwhere note < 3union allselect pnrfrom Personalwhere Lohn> 65000;Alle Elemente beider Relationen bleiben erhalten!
Differenz
except all
Atomare Formeln
| Operation | Syntax | Beispiel |
|---|---|---|
| Between | A between B and C | |
| Like (Wildcards möglich) | A like B | |
| Wildcards | ▪ % repräsentiert beliebig viele Zeichen ▪ _ repräsentiert genau ein Zeichen | select PName from Personal where Vorname like 'M%g_t |
| In | A in (b,c,… , z) | |
| Sonderbehandlung für NULL-Werte | where | select * from PMZuteilung where note is null; |
Die mit null-Werten aufgefüllten Attribute erfordern eine dreiwertige Logik
Zusätzlich zu dem Wert trueund falsekann eine Bedingung den Wert unknownliefern.
Das Ergebnis einer atomaren Formel ist
unknown, wenn ein null-Wert mit einem anderen Wert durch einen relationalen Operator verglichen wird.
Joins
| Art | Bemerkung | Beispiel |
|---|---|---|
| Join | select * from r, s where r.A = s.B | |
| Semi-Join | select r.* from r, s where r.A = s.B | |
| Innerer Theta-Join | from r inner join s on r.A > s.B | |
| Innerer Equi-Join über ein gemeinsames Attribut A | Resultatschema enthält das Attribut A genau einmal. | from r inner join s using (A) |
| Natural Join | from R natural inner join S |
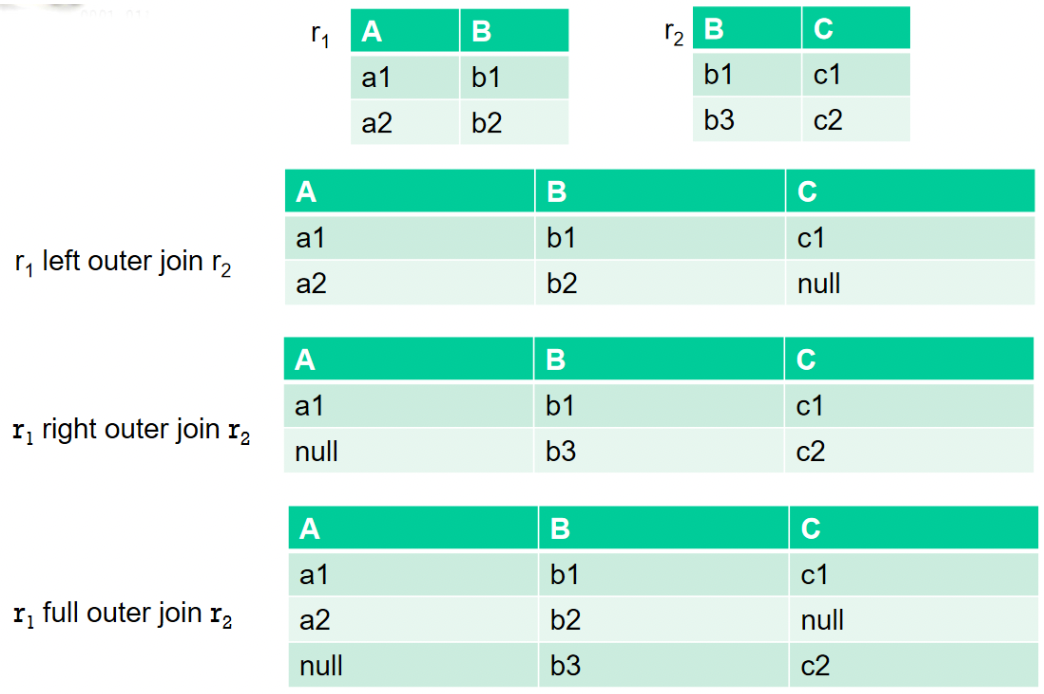
Outer-Joins
Ergebnis umfasst alle Tupel des äquivalenten inneren Join
Zusätzlich werden noch die Tupel, die keinen Join-Partner haben, in das Ergebnis aufgenommen.
Die fehlenden Werte werden mit dem Wert nullaufgefüllt.
| Art | Beispiel |
|---|---|
| left outer join | from r left outer join s on r.A = s.B |
| right outer join | from r right outer join s on r.A = s.B |
| full outer join | from r full outer join s on r.A = s.B |
Beispiel:
Skalare Aggregate
Liefert zu einer Menge/Multimenge von Werten einen Wert zurück.
- Typische numerische (unäre) Aggregate: count, sum, avg, min und max.
- Logische Aggregate (liefern true oder false): exists, every, any, some
- Weitere statistische Aggregate: variance, corr, stddev, regr_slope
Beispiel:
select count(pnr) from PMZuteilung;select min(Note), max(Note)from PMZuteilung;select count(distinct A), avg(distinct B) from r;In count(*) kann distinct nicht genutzt werden.
Unterschied von sum und avg zu count: Bei einer leeren Eingabe wird der Wert NULL und nicht die Zahl 0 zurückgeliefert.
Gruppierung (Vektoraggregate)
Beispiel:
select pnr, note, count(*)from PMZuteilunggroup by pnr, note;select note/2 as n, count(*)from PMZuteilunggroup by n;Having-Klausel
Filtern von Gruppen, die gewisse Bedingungen erfüllen, wie z. B. Anzahl der Tupel in einer Gruppe > 5.
Beispiel:
select mnr, avg(note)from PMZuteilunggroup by mnrhaving count(*) > 2;Sortierte Ausgabe
NULLS { FIRST | LAST }: Behandlung von Nullwerten , zuerst oder am Ende der sortierten Ausgabe
Syntax:
ORDER BY sort_expression1 [ASC | DESC] [NULLS { FIRST | LAST }] [, sort_expression2 [ASC | DESC] [NULLS { FIRST | LAST }] ...]Beispiel:
select * from PMZuteilungorder by Note desc, pnr;Limit-Klausel
Sinnvoll nur bei SQL-Anfragen mit order-by-Klausel.
Syntax:
limit N [offset M] - N, M sind ganze Zahlen
- Anfrage liefert aus der sortierten Ergebnisfolge das(M+1)-te, (M+2)-te, ...(M+N)-teTupel.
Beispiel:
select * from PMZuteilungorder by Note desc, pnr nulls lastlimit 5;Zusammenfassung
Zusammensetzung einer SQL-Anfrage
select Xfrom R,S,T,...where Fgroup by Yhaving Gorder by Hlimit N offset MX eine Menge von Attributen
R,S,T,… eine Liste von Relationen
Optional können bereits hier die Joins formuliert werden.
F eine Boolesche Formel
Y eine Menge von Attributen
G eine Boolesche Formel zur Filterung von Gruppen
H eine Liste von Attributen zum Sortieren
Unteranfragen
Varianten von Unteranfragen
relationerzeugende Unteranfrage (engl.: table subquery):
In SQL kann überall dort, wo bisher eine Relation steht, eine temporäre Relation in Form einer SQL-Anfrage verwendet werden.
tupelerzeugende Unteranfrage (engl.: row subquery):
In SQL kann überall dort, wo ein Tupel stehen darf, eine Unteranfrage stehen, die genau ein Tupel produziert.
werterzeugende Unteranfrage (engl. scalar subquery):
In SQL kann überall dort, wo ein Wert verlangt wird, eine temporäre Relation mit einem Attribut und einer Spalte verwendet werden.
Beispiel:
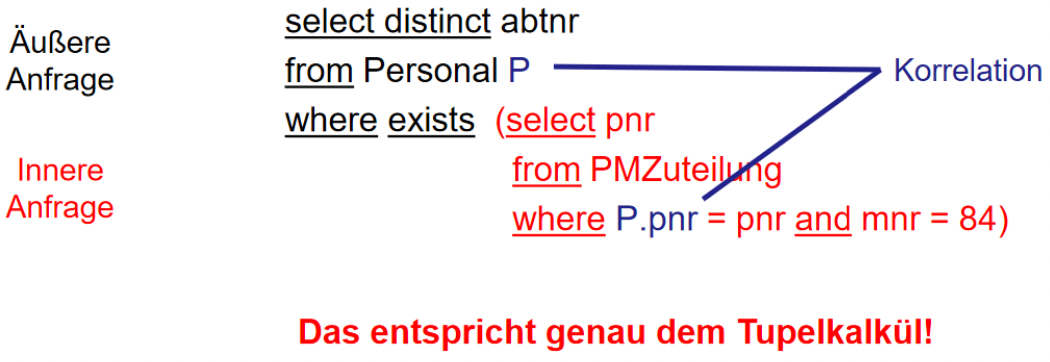
select mnrfrom PMZuteilungwhere pnr = 67 and note < (select avg(note) from PMZuteilung); select (select count(*) from PMZuteilung);Korrelierte Unteranfrage
Unteranfrage sind von der äußeren Anfrage abhängig.
Diese Auswertung ist i. A. sehr teuer und es stellt sich deshalb die Frage, ob man diese Anfragen noch anders ohne eine korrelierte Unteranfrage berechnen kann. Wenn es gelingt, spricht man vom Dekorrelieren der Unteranfrage.
Beispiel:

Diese Anfrage liefert für jede Person B mit Personalnummer B.pnr genau einen Wert!
Mit solchen Unteranfragen kann jede group-by Klausel nachgebaut werden
Bespiel:
select pnr, avg(Note)from PMZuteilunggroup by pnrselect distinct B.pnr, (select avg(Note) from PMZuteilung A where A.pnr = B.pnr)from PMZuteilung B;Unteranfragen sind ausdrucksstärker.
Unteranfragen in der where-Klausel treten sehr oft in korrelierter Weise auf.
Sichtbarkeiteiner Tupelvariable
- Eine Tupelvariableist zunächst in allen zugehörigen Unteranfragen gültig.
- Wird die Tupelvariableerneut deklariert, ist die äußere Deklaration nicht mehr sichtbar.
Unkorrelierte Unteranfragen
Wenn eine Unteranfrage unabhängig von der äußeren Anfrage ist, spricht man von einer unkorrelierten Unteranfrage.
Im Gegensatz zu einer korrelierten Anfrage ist dann eine einmalige Auswertung der Unteranfrage möglich.
Die Kosten bei der Auswertung solcher Unteranfragen sind i. A. niedrig
Relationerzeugende Unteranfragen
Statt einer persistenten Relation kann eine Unteranfrage als „temporäre“ Relation benutzt werden.
Dabei wird die Unteranfrage geklammert.
Solche Anfragen können in der From- und Where-Klausel auftreten.

Mengenwertige Unteranfragen
Durch das Schlüsselwort in kann getestet werden, ob ein Attribut einen Wert in einer Menge annimmt.

Durch Negation lässt sich auch not in testen.
Differenz mit Unteranfragen
Differenz zwischen zwei Relationen
- Verwendung von except
- Unteranfrage mit not in
- Unteranfrage mit not exists
Beispiel:
Berechne alle Angestellten, die derzeit keine Maschine bedienen können.
select *from Personalwhere pnr not in (select pnr from PMZuteilung)select *from Personal pwhere not exists (select pnr from PMZuteilung where pnr = p.pnr)Allquantifizierte Anfragen
Für den Benutzer sind allquantifizierte Anfragen besonders wichtig: alle Tupel einer Relation (Unteranfrage) erfüllen etwas.
- Berechne die Angestellten, die alle Maschinen bedienen können.
- Berechne die Studenten, die alle Vorlesungen bei Prof. Taentzer gehört haben.
Es gibt keine Allquantoren in SQL, stattdessen müssen die Anfragen auf den Existenz Operator exists abgebildet werden.
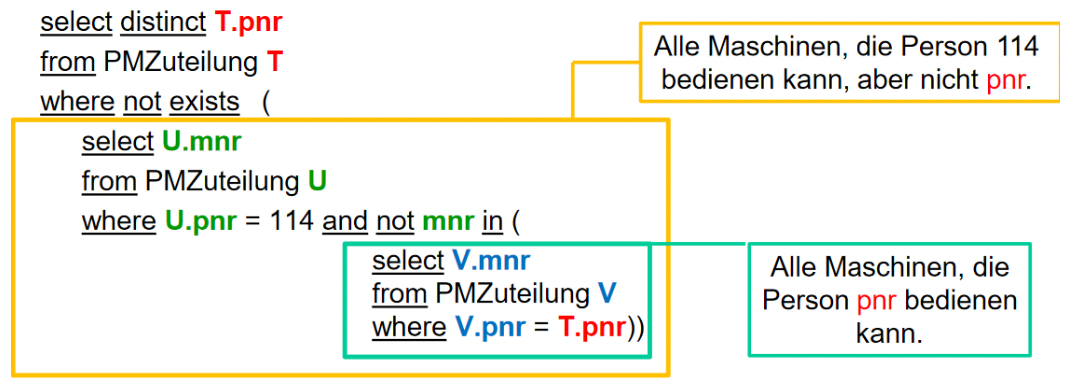
Einfache allquantifizierte Anfragen mit all
Semantik ALL
- alle Elem. true: true -
- mind. 1 Elem. false: false
- sonst: unknown
Beispiel all:
selectfrom PMZuteilungwhere note < all('{3, 4}')select *from PMZuteilung Lwhere note <= all ( select note from PMZuteilung where mnr = L.mnr)Hier gibt es noch ein Problem, wenn note = null ist.
Beispiel some/any:
Statt einer Menge mit Werten kann wiederum eine Relation mit einem Attribut verwendet werden.
select *from PMZuteilung Lwhere note < some( select note from PMZuteilung where mnr = L.mnr)Index
Beispiel:
create unique index PersonalIndex on Personal (PName,Vorname);drop index <Index-Name>Tradeof:
- Ein Index macht die Anfragen in einer Datenbank schneller.
- Ein Index macht das Einfügen in eine Datenbank langsamer.
Indexstrukturen:
- B-Bäume:Defaulteinstellung beim Erzeugen eines Index
- Hashtabellen
- GIST: Mehrdimensionale Indexe, die sich für die Indexierung von 2-dimensionalen Koordinaten eignen.
- GIN: Indexstruktur für Tabellen mit Text
- Brin: Aufteilung der Tabelle in Partitionen gleicher Größe, Abspeicherung von min- und max-Werte pro Partition
Rekursive Anfragen

Beispiel:
Beachte: with ist nur zusammen mit EINER Anfrage erlaubt.
with MitarbeiterStat(pnr, perf) as( select pnr, avg(note)from PMZuteilung group by pnr)select pnrfrom MitarbeiterStatwhere perf < (select avg(perf) from MitarbeiterStat);The following items are not allowed in a recursive with-clause (SQL server):
- SELECT DISTINCT
- GROUP BY
- HAVING
- Scalar aggregation
- TOP (= Limits)
- LEFT, RIGHT, OUTER JOIN (INNER JOIN is allowed)
- Subqueries
Sichten
Motivation
Datenschutz:
Benutzer sollen nur einen kleinen Bereich der Daten einsehen oder beschreiben.
Implementierung der logischen Datenunabhängigkeit:
Eine Anwendung muss i. A. nicht angepasst werden, wenn eine Relation sich ändert.
Bei lesenden Anfragen: Keine Unterscheidung zwischen Sichten und Relationen (Unterstützung von Änderungsoperationen in Sichten).
Sichten anlegen:
Syntax:
create view <Sichtname> [(<Attributname>[,<Attributname>]*)] as <Subquery> [with check option]Beispiel:
create view TopPMZ as select * from PMZuteilung where Note < 3 with check option;Schlüsselwort with check option:
Nur die Datensätze können in eine Sicht eingefügt werden, die bei einer Suche in der Sicht wieder gefunden werden können.
➔ Dies ist die einzig sinnvolle Variante einer Sicht.
Sicht löschen:
drop view <Sicht-Name>Updates nicht immer möglich
Problem:
Eindeutige Delegation der Änderung an Relationen
Beispiel:
create view agg_view asselect pnr, count(*) from PMZuteilung group by pnr;insert into agg_view values (77, 42);Oracle unterstützt Änderungen nur dann, wenn
- keine Aggregatfunktion
- keine Anweisungen mit distinct, group by, having, union und minus
- from-Klausel mit nur eine Relation
- ein Schüssel der Relationen in der select-Klausel
Materialisierte Sichten
Beispiel:
create materialized view magg_view as select pnr, count(*) from PMZuteilung group by pnr;Dadurch werden die Ergebnisse der SQL-Anfrage unter dem Namen magg_view explizit gespeichert.
Im Gegensatz zu einer normalen View kann man keine Änderungsoperationen auf einer materialisierten View durchführen.
Soll die View neu berechnet werden, muss dies explizit vom Benutzer ausgelöst werden.
refresh materialized view magg_view;Namensräume
Motivation: Vermeidung von Namenskonflikten bei Tabellen, Sichten und Indexen
Syntax:
create schema <Name> [authorization <Benutzer>] [schema_element]*Beispiel:
create schema MyERP create table PMZuteilung …. create view TopPMZ …. create index indx_pmz ….Wertebereiche
Einschränkung bestehender Datentypen durch Hinzufügen von Integritätsbedingungen.
Verwendung in verschiedenen Relationen
Syntax:
create domain <Name> [as] <Datentyp> [<Defaultwert>] [<Integritätsbedingung>]*Beispiel:
create domain Adresse varchar(50) default 'Marburg'Weitere Funktionalität:
- alter domain …
- drop domain …
Verfügbare Datentypen
Eine kleine Auswahl (aus dem SQL Standard):
bigint, bit, bit varying, boolean, char, character varying, character, varchar, date, double precision, integer, interval, numeric, decimal, real, smallint, time, timestamp, xml, json
Jedes System hat zusätzlich noch spezifische Datentypen:
PostgreSQL → siehe Benutzermanual
Beispiel: date, timestamp, serial
Klassen von Integritätsbedingungen
Statische Bedingungen
Definiert der erlaubten Datenbankzustände
- Primärschlüssel (primarykey)
- Eindeutigkeit (unique)
- Fremdschlüssel (foreignkey)
- Check-Bedingungen
Dynamische Bedingungen
Definition der erlaubten Zustandsänderungen in einer Datenbank.
Zwei Zustände können möglich sein, aber nicht der Übergang des einen Zustands in den anderen.
Check-Bedingungen
Beispiel:
create table PMZuteilung (pnr int, mnr int, note int check(note> 0 andnote< 7),...)Eine Integritätsbedingung kann nun mit folgenden Schlüsselworten versehen werden:
not deferrable
Sofortige Überprüfung nach einer Änderung (immer!)
deferrable
Verzögerte Überprüfung möglich
deferrable initially deferred
Überprüfung nur am Ende der Transaktion.
deferrable initially immediate
Überprüfung vor der Änderung.